 HTTP的原理和工作机制
HTTP的原理和工作机制
# 什么是Http
HTTP:是英文HyperText Transfer Protocol的缩写,翻译过来就是超文本传输协议.
但是翻译过来还是让人摸不着头脑,只能大概知道这是一种协议,因此我们进一步把超文本传输协议拆成超文本,传输,协议三个词来进行理解
超文本:最早【文本】就是我们通常了解的字符文字,但是随着通讯技术的发展.图片,音频,视频甚至压缩包都纳入进来了,出现了【超文本】概念, 它是一种将图片,音频,视频等【文本】内容混合在一起,并引入【超链接】,使不同的【文本】直接可以跳转的一种文本.HTML就是一种典型的超文本.传输:传输比较容易理解,就是把东西从一端传到一端.协议:这个也比较容易理解,就是咱们平常理解协议的意思,一种被双方都接受的规范.
通过上面的解释,我们大概可以理解,HTTP就是一种能够传输文本,图片,音频,视频等资源一种协议规范.
# Http的工作过程
我们程序员在平常的开发过程中,会经常接触到HTTP,下面我们简单举两个例来简单理解HTTP的工作过程
- 浏览器输入网址,打开网页
- Android应用发送请求,返回对应内容
以下是浏览器输入网址,打开网页的一个过程有以下步骤(只解释HTTP的流程,真实情况下还涉及到DNS的问题,暂时不讨论)
- 浏览器输入网址
- 浏览器发送请求到服务器
- 服务器处理浏览器请求,返回响应结果
- 浏览器接收到响应,渲染页面

# URL和HTTP报文
# URL
根据上面的案例,我们在浏览器中输入一个短短的网址URL,怎么就获取到这么多东西呢,下面我们网址的URL进行下分析

从上面我们可以看出URL由3部分组成,其实真实情况下应该有4部分组成,分别是协议类型,服务器主机,端口,路径path
其中http端口为80,https端口为443,在默认的情况下都是省略了,
URL标准的请求应该为
http://oopanda.cn:80/auth/user?id=100&group=1
# HTTP报文
使用网页或者使用postman调用接口的时候我们经常会看到以下这些东西,这些东西是什么呢?
Http/1.1 200 OK
Access-Control-Allow-Credentials:true
Access-Control-Allow-Origin:https://oopanda.cn
Cache-Control:no-cache, no-store, max-age=0, must-revalidate
Connection:keep-alive
Content-Length:967
Content-Type:application/json;charset=UTF-8
Date:Thu, 05 Jan 2023 07:03:54 GMT
Expires:0
Pragma:no-cache
Server:nginx/1.13.3
2
3
4
5
6
7
8
9
10
11
其实这些东西就是HTTP报文,就是http应用直接发送的数据块,分为请求报文和响应报文,下面是通过抓包工具wireshark抓取
# 请求报文
GET /user?id=100&group=1 HTTP/1.1
Accept: */*
Referer: http://oopanda.cn/auth
Accept-Language: en-US
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
Accept-Encoding: gzip, deflate
Host: oopanda.cn
Connection: Keep-Alive
Cookie: xxxxxxxxxxxxxxx
2
3
4
5
6
7
8
9
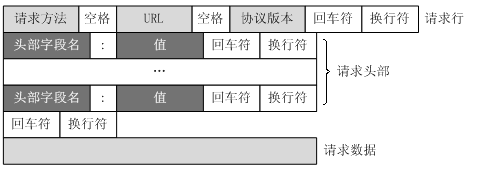
HTTP的请求报文由四部分组成:请求行,请求头,空格,请求体
请求行:由请求方法,path,http版本组成请求头:由多个key-value值组成常见的有Host,Content-Type,User-Agent等,下面会具体介绍空格:请求报文使用空格将请求头和请求体分割开,无其他意义请求体:GET方法没有携带数据,POST/PUT方法会携带body数据
# 响应报文
HTTP/1.1 200 OK
Bdpagetype: 1
Bdqid: 0xacbbb9d800005133
Cache-Control: private
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html
Cxy_all: baidu+f8b5e5b521b3644ef7f3455ea441c5d0
Date: Fri, 12 Oct 2020 06:36:28 GMT
Expires: Fri, 12 Oct 2020 06:36:26 GMT
Server: BWS/1.1
Set-Cookie: delPer=0; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=0; path=/
Set-Cookie: H_PS_PSSID=1433_21112_18560_26350_27245_22158; path=/; domain=.baidu.com
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
<!DOCTYPE html>
<!--STATUS OK-->
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21

看上去响应报文和请求报文的接口差不多,其实两者的组成接口的确差不多,响应报文由四部分组成:状态行,响应头,空格,响应体
状态行:由协议版本,状态码,状态值组成响应头:由多个key-value值组成空格:用于将响应头和响应体分割开,无其他意义请求体:响应数据,可能是html,json,图片等
在上面咱们已经简单了解了请求报文和响应报文的组成,下面咱们具体了解下其中的具体组成成分请求方法,头信息等
# HTTP的请求方法
GET请求:由path和params两种添加参数的方式,无body主要用于获取资源的接口,也是最常用的请求方法POST请求:增加或者修改资源的接口PUT请求:修改资源的接口,和POST的不同是PUT是幂等,也就是多次执行和一次执行是一样的效果DELETE请求:删除资源,没有body,是幂等HEAD请求:很少使用,不会返回body,主要是获取报文的头信息,可以用于下载OPTIONS请求:用于获取OPTIONS都支持哪些HTTP请求方法,爬虫的时候用过
# 状态码
1XX(临时响应):一种临时性的响应状态码100(继续):服务器收到一部分请求,告诉客户端继续请求
101(切换协议):客户端要求服务器切换协议,服务端接收到,并且已经准备好了
2XX(成功):表示成功处理了请求的状态码200(成功):服务器已经成功接收到请求并处理好了
201(已创建):请求成功,并且创建了新数据,POST新增数据的时候会返回
202(已接收):服务器已经接收了请求,但是还未处理
3XX(重定向):重定向到新的网址300(多种选择):针对请求,服务器可执行多种操作,客户端可以根据UA或者其他方式告诉服务端
301(永久移动):请求的网址已经被永久的移到了新网址,服务器返回此响应的时候会自动转到新网址
4XX(请求错误):客户端出现的请求错误400(错误请求):客户端发送了服务器不理解的语法或者请求参数有错
401(未授权):客户端没有或者发送了错误的认证信息返回的错误
403(禁止):服务器接收了请求,但是它拒绝了,原因有很多种,可能是请求过于频繁
404(未找到):服务器没找到资源,一半是url拼接错误
405(方法禁止):请求方法错了,需要POST请求方法的,使用了GET
5XX(服务器错误):服务器出现的错误500(服务器内部错误):服务器内部遇到错误
# 头信息(Header)
头信息主要是用来传递http的元数据(metadata).
# 常用头信息
# Host
Host:服务器主机地址,需要注意的是host不是用来ip寻址的,寻址是发送报文前通过DNS来完成的.
为什么会还要这个host呢,是因为可能会存在1个ip多个虚拟服务器,如果没有host无法精确定位到具体的虚拟机服务器
# Content-Length(内容长度)
Content-Length:用来标记发送内容的字节长度的,如果Content-Length小于实际内容的长度,则发送的内容将不完整,
如果Content-Length大于实际内容的长度,服务器会响应超时报错,因为服务端/客户端读取到消息结尾后,会等待下一个字节,一直等待不到直至超时.
如果不确定Content-Length长度我们需要使用
Transfer-Encoding:chunked
# Transfer-Encoding(传输编码)
Http/1.0后引入了长链接的概念,通过Connection: keep-alive 实现,服务端和客户端通过发送这个头部信息告诉对方不需要断开TCP连接,后面继续使用,
Http/1.1后改成默认规则,只要不发送Connection: close,默认保持长链接.
持续的长链接需要服务器/客户端在开始发送消息的时候就需要知道内容的长度定义好Content-Length,但是对于动态生成的内容来说,在内容完成之前这个Content-Length是不可知的,
所以在Http/1.1就引入了Transfer-Encoding:chunked(分块传输编码)概念,消息内容会分成数量未定的块数,并以最后一个为0结束发送
以下是Transfer-Encoding的几种定义方法:
Transfer-Encoding:chunked:消息内容会分成数量未定的块数,并以最后一个为0结束发送,Content-Length在这种情况下不会被发送.Transfer-Encoding:compress:采用 Lempel-Ziv-Welch (LZW) 压缩算法,这种内容编码方式已经被大部分浏览器弃用.Transfer-Encoding:deflate:采用 zlib 结构 (在 RFC 1950 中规定),和 deflate 压缩算法(在 RFC 1951 中规定).Transfer-Encoding:gzip:采用 Lempel-Ziv coding (LZ77) 压缩算法,以及 32 位 CRC 校验的编码方式.这个编码方式最初由 UNIX 平台上的 gzip 程序采用.Transfer-Encoding:identity:指代未经过压缩和修改.
# Content-Type(内容类型)
在Http中通过Content-Type表示消息内容的类型信息,被用来告诉服务端如何处理数据,以及告诉客户端如何解析数据,
以下是Content-Type常用格式
Content-Type: text/html:HTML格式,常用于浏览器页面响应Content-Type: application/json:JSON数据格式,用于web api的响应,或者post/put请求Content-Type: application/x-www-form-urlencoded:普通表单, encode URL格式 提交的body拼成name=q&url=2类型,只能传文本Content-Type: multipart/form-data:表单进行文件上传时,就需要使用该格式,将内容分多个部分传输每部分内容的形式,使用 boundary 对它们进行分隔Content-Type: image/jpeg:jpg图片格式Content-Type: text/plain:文本格式Content-Type: text/XML:XML格式
# User-Agent(用户代理)
User-Agent(用户代理),简称 UA,这是一个特殊字符,网站服务器通过识别UA,来确定用户使用的操作系统版本,CPU类型,浏览器版本信息等.
H5常常通过UA判断设备是否是手机 ,爬虫也常用来修改UA绕过网站的反爬(只是爬虫和反爬的第一步).
# Location(重定向)
告诉客户端加载另外一个url,通常是在301重定向的时候使用
# Range/Accept-Range/Content-Range
Range: bytes=<start>-<end>:请求报文出现,表示要取哪段数据Accept-Range: bytes:响应报文出现,表示服务器支持按字节取范围数据Content-Range:<start>-<end>/total:响应报文出现,表示发送的是哪段数据
以上头信息常用于断点上传,多线程下载等.
# Accept
客户端能接受的数据类型,如 text/html
# Accept-Charset
客户端接受的字符集,如 utf-8
# Accept-Encoding
客户端接受的压缩编码类型,如 gzip
# Content-Encoding
压缩类型,如 gzip
# Cache(缓存)/Buffer(缓冲)
Cache用过的东西,待会可能还会用的, Buffer,针对工作流的,还没用过的东西,一定会用的,比如视频的缓冲
Cache-Control:no-cache:可以缓冲Cache-Control:no-store:不要缓存Cache-Control:max-age:失效前使用缓存
Last-Modified:最近什么时候改变的 if- Modified-Since Cache-Control是http1.1为了弥补expires而产生的
推荐阅读